Performance¶
Table of Contents
Documentation Conventions¶
Commands and keywords are in this
font.$OFFLOAD_HOMEis set when the environment file (offload.env) is sourced, unless already set, and refers to the directory namedoffloadthat is created when the software is unpacked. This is also referred to as<OFFLOAD_HOME>in sections of this guide where the environment file has not been created/sourced.Third party vendor product names might be aliased or shortened for simplicity. See Third Party Vendor Products for cross-references to full product names and trademarks.
Introduction¶
This guide describes and demonstrates a range of performance optimizations that are available when using Gluent Data Platform. Familiarity with Gluent Data Platform Concepts is a pre-requisite.
Optimization Goals¶
When a query is executed against a hybrid view and Oracle Database determines it needs to retrieve data from the hybrid external table, a “distributed” query has begun. Oracle Database will wait until the rows from the backend system are returned to the hybrid external table by Smart Connector, the key component of Gluent Query Engine. When the rows are received, Oracle Database will ingest them through its external table interface.
There are four areas of potential bottleneck in this process:
The volume of data/number of rows returned to Oracle Database
The ingestion rate of the rows received by Oracle Database
The time taken to process the data in the backend system
The time taken to transfer the rows from the backend system to the Oracle Database instance
It follows that the performance tuning goals should be:
Reducing the volume of data/number of rows returned by pushing processing down to the backend
Increasing the speed of ingestion by returning only what is needed from the backend
Increasing speed of backend processing
Increasing throughput from the backend system to the RDBMS
Reducing the Volume of Rows Returned by Pushing Processing Down to the Backend System¶
The most important optimization goal is to reduce the number of rows retrieved from the backend system. Gluent Query Engine is able to push processing to the backend under several scenarios:
Filter (predicate) pushdown
Join filter pulldown
Aggregation (group by) pushdown
Join pushdown
Aggregation and join pushdown
In all cases the pushdown/pulldown optimizations utilize backend system resources for processing data and reduce the volume of data transported back to the RDBMS.
Tip
Pushing processing also offloads processing power to the backend system and can reduce CPU consumption in the RDBMS. An example is that after hybridization, a CPU-hungry serial scan in Oracle Database can become a parallel scan in the backend with massively-reduced Oracle Database CPU consumption.
Note
The MONITOR hint is only included in the examples to enable a report to be generated with Hybrid Query Report after each query (for investigation purposes). Also note that these examples use schema-references to denote ownership of the query objects. As described in Transparent Query, this isn’t mandatory and all references can be removed and resolved to the hybrid schema itself by modifying the “current schema” for the database session.
Predicate Pushdown¶
Below is an example of a hybrid query that will benefit from predicate pushdown:
SQL> SELECT /*+ MONITOR */ *
FROM sh_h.sales
WHERE time_id <= DATE '2011-01-01'
AND prod_id = 23;
Both of the predicates in the example will be pushed to the backend system (Google BigQuery in this example) for filtering. The impact of the pushdown can be investigated by generating a hybrid query report using Gluent Query Engine’s Hybrid Query Report. See Hybrid Query Report for instructions on how to generate a report.
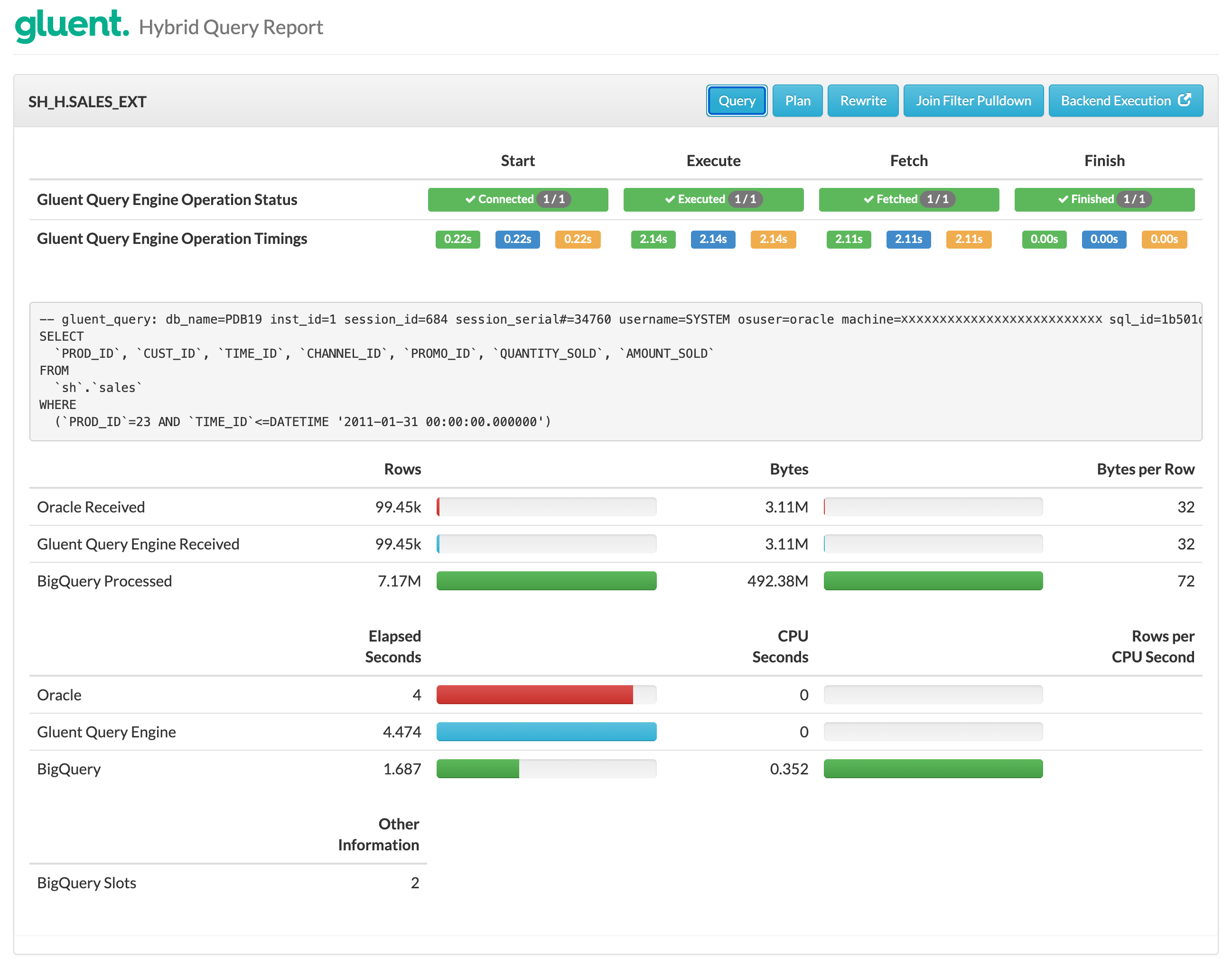
Notice:
The query displayed in the report shows that Gluent Query Engine has included both predicates in the Google BigQuery query
Google BigQuery has scanned 7.17M rows but filtered those down to 99.45k after applying the predicates
Table 1 below lists all of the Oracle Database functions and expression formats supported for predicate pushdown by Gluent Query Engine. Inputs to functions and expressions are expressed as either “column” (i.e. table or view column) or “value” (i.e. literal value or bind variable).
Table 1: Supported Predicate Pushdown Functions and Expressions¶
Class |
Function/Expression |
UDF |
Notes |
|---|---|---|---|
Arithmetic |
|
||
|
|||
|
|||
|
|||
|
|||
Operator |
|
||
|
Values can be of any data type that supports comparison (see
Supported Predicate Pushdown Data Types)
|
||
|
Disabled by default. Can be enabled with the
Setting |
||
Conversion |
|
||
|
|||
|
|||
|
Format masks containing one or more of the following elements are supported:
|
||
|
Format masks containing one or more of the following elements are supported:
|
||
|
|||
|
Format masks containing one or more of the following elements are supported:
|
||
|
|||
|
Format masks containing one or more of the following elements are supported:
|
||
Date/Timestamp |
|
||
|
Supported modifiers are: |
||
|
Supported modifiers are: |
||
|
|||
|
|||
|
|||
|
Defaults to |
||
|
Supported modifiers are: |
||
|
Defaults to |
||
|
Supported modifiers are: |
||
String |
|
||
|
|
UDF is for Impala only (not required for BigQuery, Snowflake or Synapse) |
|
|
|||
|
Enabled for pushdown to BigQuery, Snowflake and Synapse
|
||
|
Enabled for pushdown to BigQuery, Snowflake and Synapse
|
||
|
Supports the |
||
|
|||
|
|||
|
|
UDF is for Impala only (not required for BigQuery, Snowflake or Synapse) |
|
|
Supported attributes are: |
Functions and expressions will be evaluated by Gluent Query Engine and pushed down as literal predicates whenever it is possible and safe to do so. In all other cases, functions and expressions will be pushed down for evaluation by the backend in the appropriate SQL dialect. Note that <value> expressions listed above can be either literal values or bind variables.
Supported Predicate Pushdown Data Types¶
Most data types are supported for general predicate pushdown (i.e. of the form <column> <operator> <value>), although there is greater support for values expressed as literals than bind variables (the same is also true for function and expression pushdown that include literal or bind values as inputs). For literal values, Gluent Query Engine will not push down predicates for RAW or INTERVAL [YEAR TO MONTH|DAY TO SECOND] data types. For bind variables, Gluent Query Engine will not push down predicates for RAW, INTERVAL [YEAR TO MONTH|DAY TO SECOND], BINARY_[FLOAT|DOUBLE] or TIMESTAMP WITH TIME ZONE data types. Predicates with LOBs are not supported by Oracle Database and therefore are not applicable to Gluent Query Engine’s predicate pushdown.
Join Pushdown¶
Below is an example of a hybrid query that will benefit from join pushdown:
SQL> SELECT /*+ MONITOR */
s.time_id
, s.promo_id
, SUM(s.quantity_sold * c.unit_price) AS sales_revenue_list
, SUM(s.amount_sold) AS sales_revenue_actual
, SUM(s.quantity_sold * c.unit_cost) AS sales_revenue_cost
FROM sh_h.sales s
INNER JOIN
sh_h.costs c
ON ( s.channel_id = c.channel_id
AND s.prod_id = c.prod_id
AND s.promo_id = c.promo_id
AND s.time_id = c.time_id )
WHERE s.time_id < DATE '2011-02-01'
GROUP BY
s.time_id
, s.promo_id
ORDER BY
s.time_id
, s.promo_id;
The query is first executed without any of the objects required for join pushdown existing. The hybrid query report shows the following.
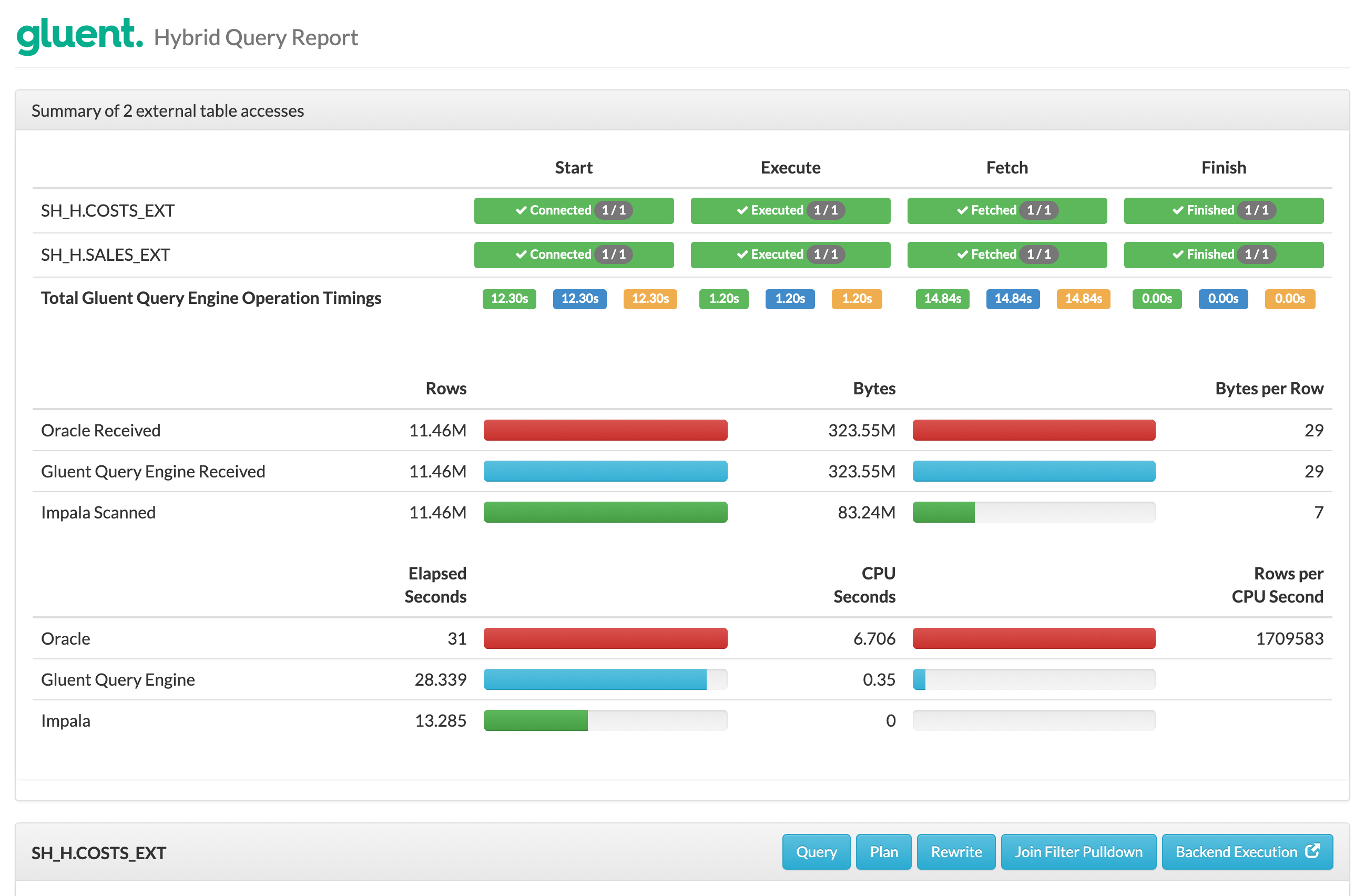
Notice:
Two external tables are processed, sending back approximately 11.46M rows to Oracle Database combined
Oracle Database performs the join operation, discarding any non-matching rows
Gluent Query Engine’s Operation Timings total over 28 seconds
By using present with the extended --present-join Present Join Grammar, Gluent Offload Engine creates hybrid objects in the RDBMS and a view in the backend system to support the pushdown of the join processing. See Presenting Joins for further details.
For this example, using a Cloudera Data Hub backend, the following present join command was issued:
$ ./present -t sh.sales_costs_join -xf \
--present-join="table(sales) alias(s) project(*)" \
--present-join="table(costs) alias(c) inner-join(s) join-clauses(time_id,channel_id,prod_id,promo_id) project(*)"
The same hybrid query was executed and the resulting hybrid query report shows the following.
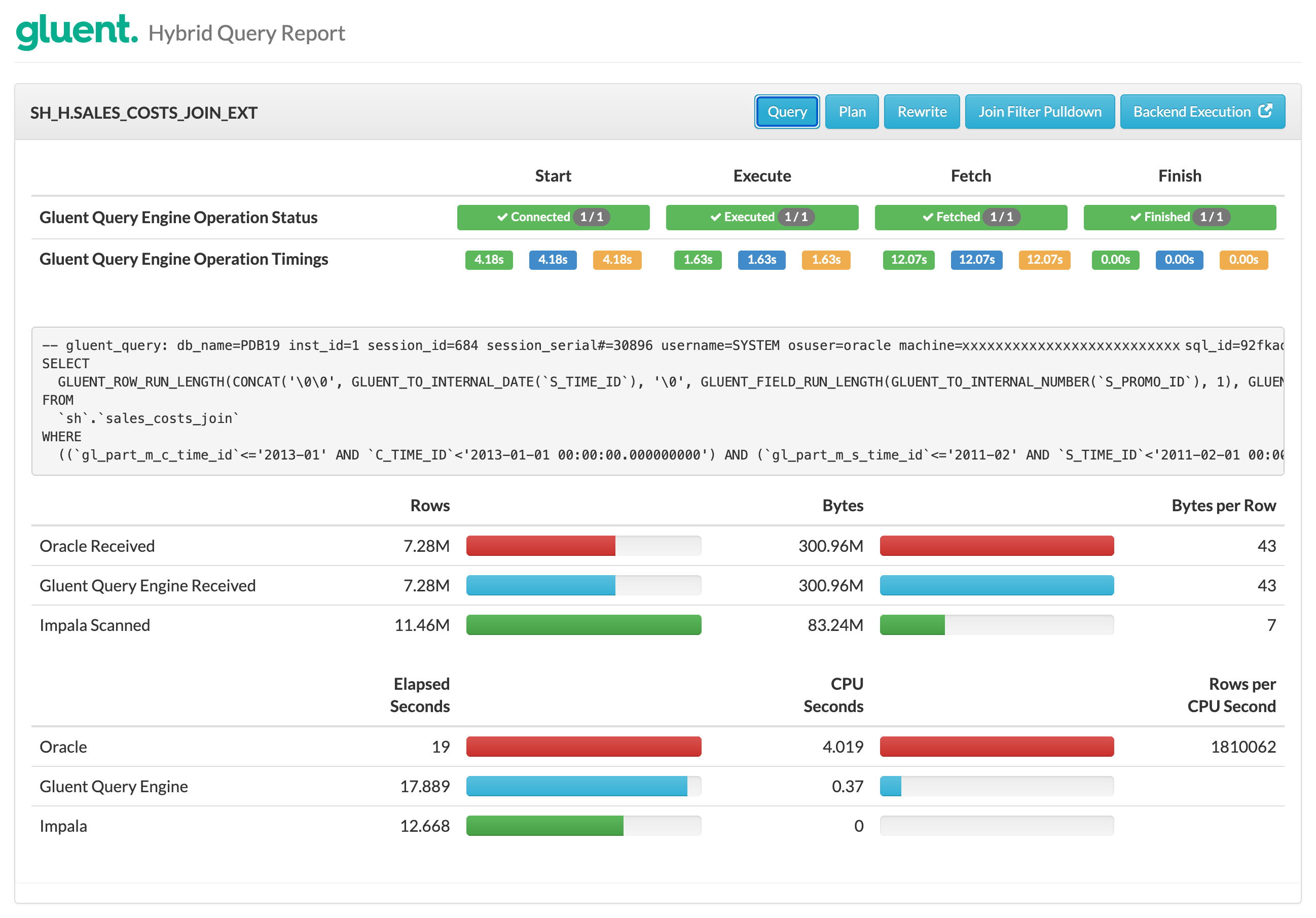
Notice:
A single external table is accessed to return the joined rowsource
The Impala query displayed in the report shows the SALES_COSTS_JOIN view is queried, thereby performing the join operation in Hadoop
Only the results of the join are returned to the Oracle Database instance: 7.28M rows (compared with 11.46M without join pushdown)
Gluent Query Engine Operation Timings total under 18 seconds (compared with over 28 seconds without join pushdown)
Materialized Join Pushdown¶
Further efficiencies can be realized by materializing the results of the join in the backend system in a table rather than using a logical view.
Returning to the non-materialized join pushdown example from above, the Plan section in the hybrid query report shows the following.
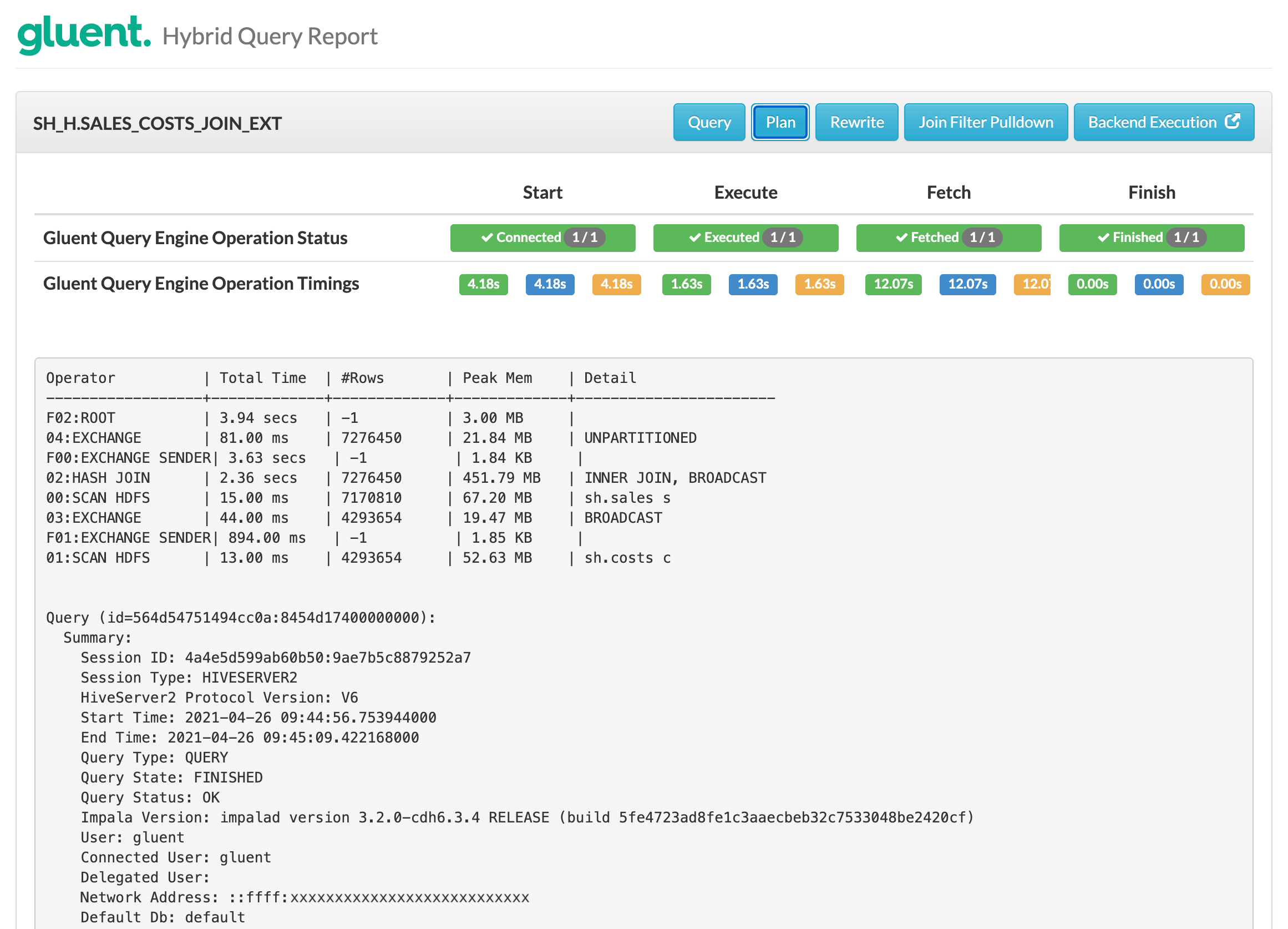
Notice:
Two SCAN HDFS operations on the sh.sales and sh.costs tables are performed
The results are joined by Impala before returning the matching 7.28M rows
The join pushdown objects were recreated and materialized using offload with the extended --offload-join Offload Join Grammar (see Offloading Joins for further details) as follows:
$ ./offload -t sh.sales_costs_join -xf \
--offload-join="table(sales) alias(s) project(*)" \
--offload-join="table(costs) alias(c) inner-join(s) join-clauses(time_id,channel_id,prod_id,promo_id) project(*)"
The hybrid query was re-executed and the Plan section in the resulting hybrid query report shows the following.
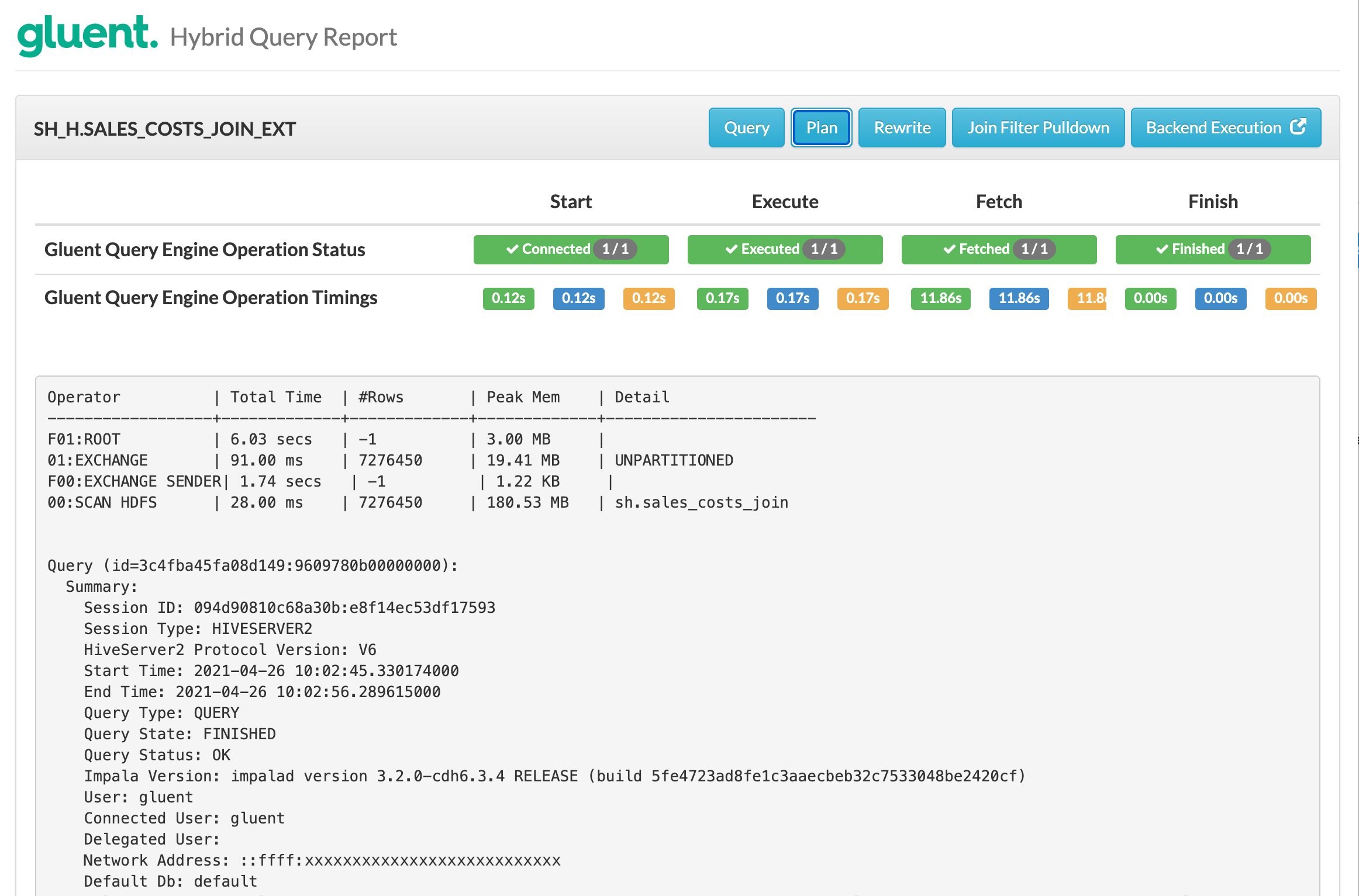
Notice:
A single SCAN HDFS operation on the sh.sales_costs_join table is performed
The elapsed time of the Gluent Query Engine execute phase is reduced to 0.17 seconds (compared with 1.63 seconds when the join was not materialized)
Adaptive Join Filter Pulldown (JFPD)¶
In addition to pushing predicates and projections on an offloaded table to the backend system, Gluent Query Engine is also able to pulldown predicates on tables that are joined to the offloaded table. This enables the backend table to be pre-filtered and return a smaller dataset. The following query illustrates this optimization:
SQL> SELECT /*+ MONITOR */ SUM(s.amount_sold)
FROM sh_h.sales s
, sh.times t
WHERE s.time_id = t.time_id
AND t.calendar_year = 2012;
Notice that the CALENDAR_YEAR predicate is applied to the SH.TIMES table which has not been offloaded.
The Hybrid Query Report shows the following:
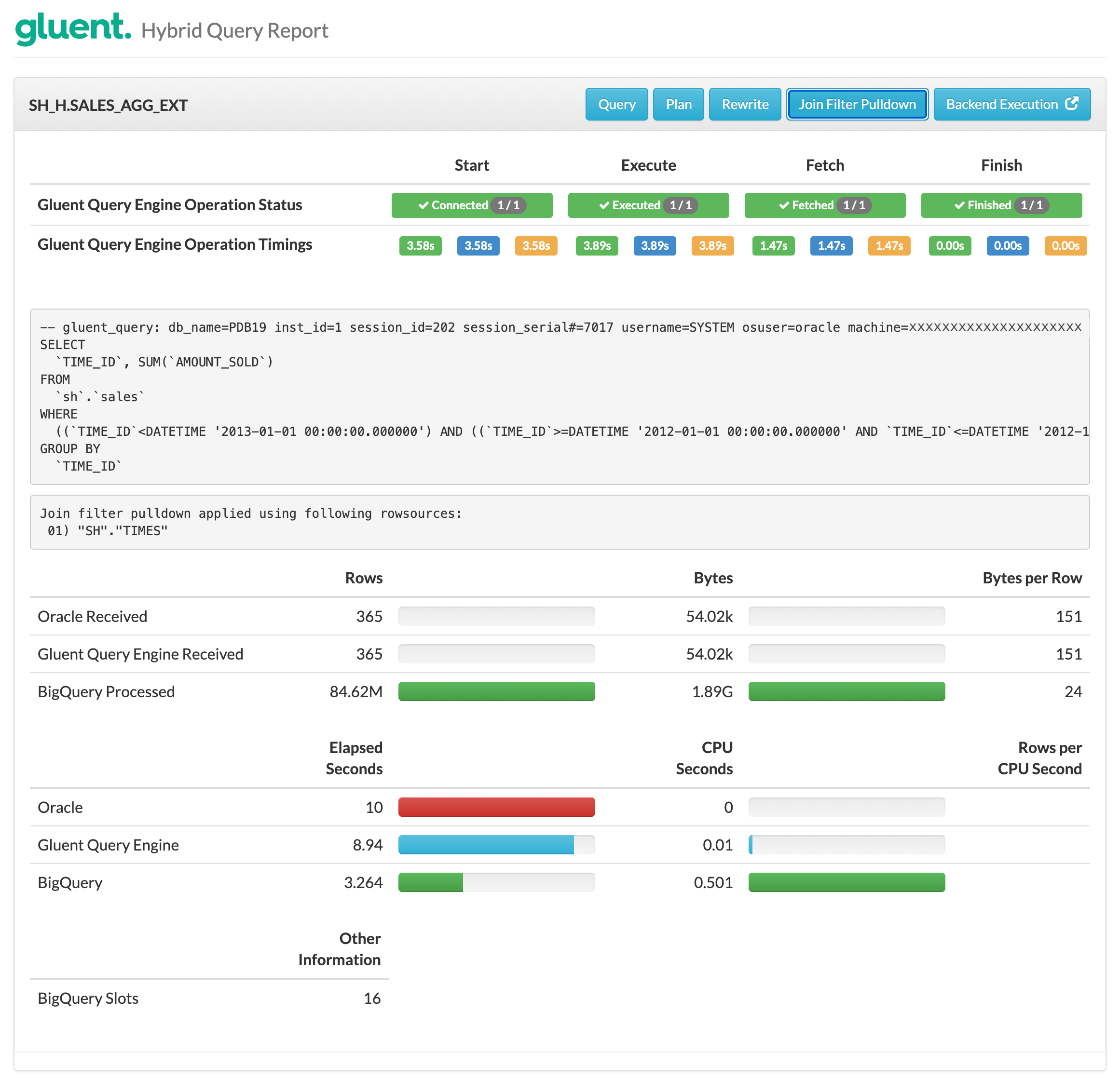
Notice:
The Join Filter Pulldown section indicates the optimization has been applied
The Query displayed shows the presence of a TIME_ID predicate on the offloaded SALES table even though none was supplied in the hybrid query
The range of TIME_ID values to be applied to SALES is constructed by querying SH.TIMES in the Oracle Database instance with the predicates on SH.TIMES. The matching TIME_ID values are pulled down and applied to the SALES table in the backend query, in this example Google BigQuery, as a combination of a range predicate and an IN-LIST predicate
Advanced Aggregation Pushdown (AAPD)¶
In addition to offloading filters to the backend, Gluent Query Engine is able to push CPU-intensive workloads such as aggregations to the backend system. Additional hybrid objects are automatically created during an Offload or Present operation (and custom aggregation objects can additionally be created as described in Custom Advanced Aggregation Pushdown Rules). Using the previous SALES offload example, the additional objects created to support aggregation pushdown are as follows.
Backend System¶
Optional conversion view to handle column names that are incompatible with the RDBMS
Oracle Database¶
Views SH_H.SALES_AGG and SH_H.SALES_CNT_AGG (hybrid view)
Tables SH_H.SALES_AGG_EXT and SH_H.SALES_CNT_AGG_EXT (preprocessor hybrid external table)
Advanced Query Rewrite Equivalences SH_H.SALES_AGG and SH_H.SALES_CNT_AGG (known as a rewrite rule for ease of reference)
The SALES_AGG aggregated view of the data will include:
All columns from SALES
Aggregation columns specified in
--aggregate-byA default “count star” column
A default AVG, MIN, MAX, COUNT, SUM aggregate for all numeric columns
A default MIN, MAX, COUNT aggregate for all other non-numeric columns
Warning
The hybrid aggregation objects should not be referenced directly in user queries. Instead, aggregation pushdown occurs transparently when aggregate queries are executed against base hybrid views such in the following examples.
Simple count(*):
SQL> SELECT /*+ MONITOR */ COUNT(*)
FROM sh_h.sales;
Aggregate query with a join to a dimension:
SQL> SELECT /*+ MONITOR */
t.calendar_year
, s.prod_id
, COUNT(*)
FROM sh_h.sales s
, sh.times t
WHERE s.time_id = t.time_id
GROUP BY
t.calendar_year, s.prod_id;
Using ANSI syntax:
SQL> SELECT /*+ MONITOR */
t.calendar_year, s.prod_id, COUNT(*)
FROM sh_h.sales s
INNER JOIN
sh.times t
ON (s.time_id = t.time_id)
GROUP BY
t.calendar_year, s.prod_id;
Count Distinct:
SQL> SELECT /*+ MONITOR */
t.calendar_year
, COUNT(DISTINCT s.time_id)
FROM sh_h.sales s
, sh.times t
WHERE s.time_id = t.time_id
GROUP BY
t.calendar_year;
Rollup:
SQL> SELECT /*+ MONITOR */
t.calendar_month_number
, t.calendar_year
, COUNT(*)
FROM sh_h.sales s
, sh.times t
WHERE s.time_id = t.time_id
AND t.calendar_year = 2012
GROUP BY
ROLLUP(t.calendar_month_number, t.calendar_year);
Taking the Rollup example executed against a Hadoop-based backend, the hybrid query report shows the following:
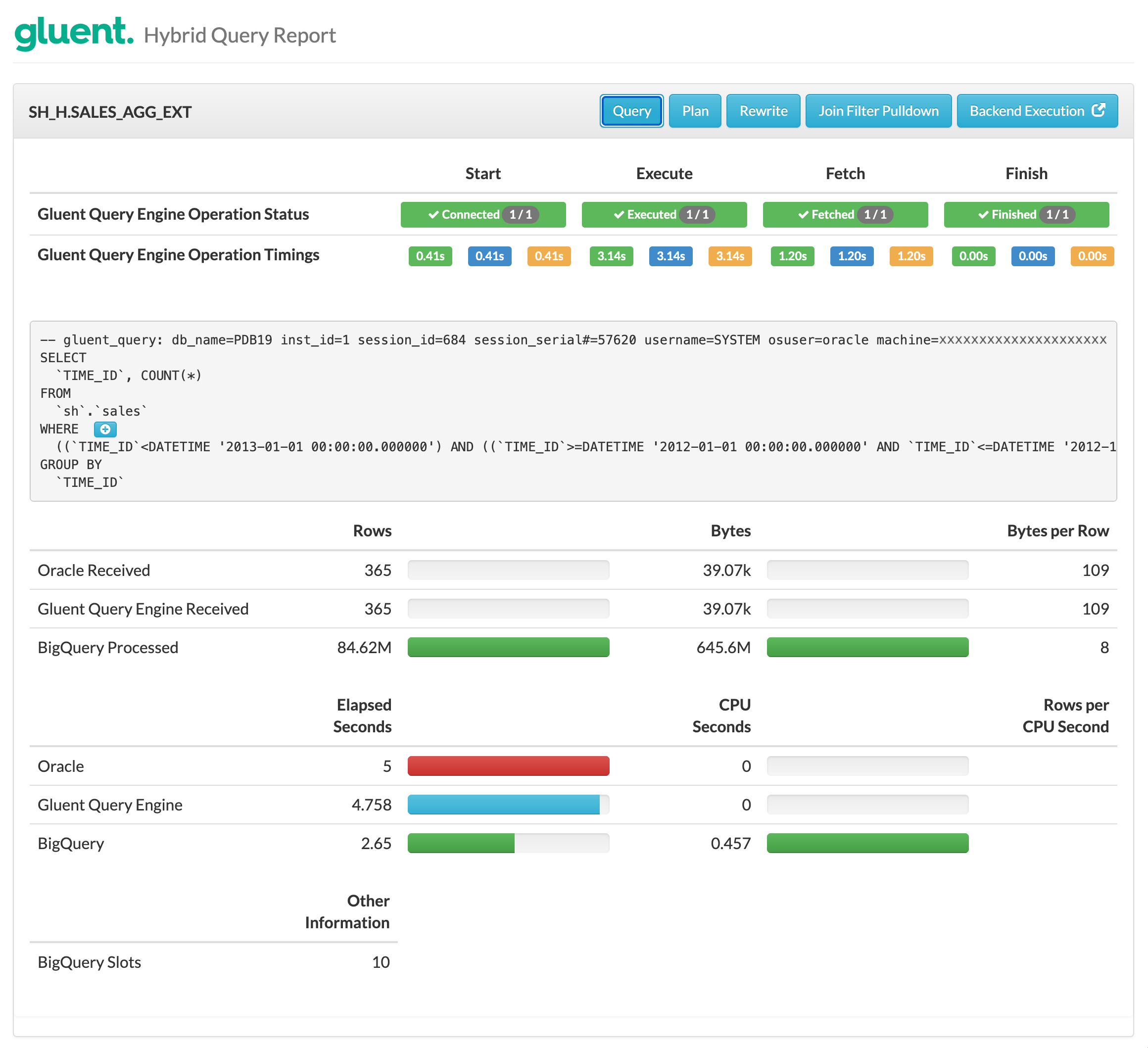
Notice:
An Advanced Aggregation Pushdown hybrid external table was used rather than the base hybrid external table
The BigQuery query generated by Gluent Query Engine includes a
GROUP BYGoogle BigQuery scanned 84.62M rows but only returned the results of the aggregation to Gluent Query Engine; in this case just 365 rows
The Rewrite section (not shown in screenshot) shows the results of the transparent rewrite of the SQL referencing the SH_H.SALES hybrid view to reference the SH_H.SALES_CNT_AGG hybrid view
Multi-table joins and outer joins are supported for rewrite (if a suitable aggregation rewrite rule exists) and ANSI-join syntax will be matched to equivalent rules that are expressed in Oracle SQL join syntax.
Restrictions¶
Aggregation pushdown is primarily restricted by Oracle’s Advanced Query Rewrite engine and what it will consider safe or valid to rewrite. In addition to this, some of the Oracle Database metadata used by Advanced Query Rewrite (constraints, dimensions, hierarchies etc) does not apply to the hybrid external table created by the Gluent Offload Engine, although a lot can still be achieved when some of the functional dependencies can be determined (e.g. dimension tables with primary keys are in Oracle Database, fact tables with foreign keys have been offloaded).
Oracle Advanced Query Rewrite will not consider queries with multiple COUNT(DISTINCT) projections safe to rewrite unless all COUNT(DISTINCT) columns are satisfied from a single table in the query (either an offloaded table or a single dimension/lookup table with functional dependencies such as a primary key join).
Every aggregation query rewrite rule is created as a GENERAL rule (rather than RECURSIVE), meaning that while source queries can be rewritten to match equivalence rules, the resulting destination SQL will not itself be rewritten to find further rewrite opportunities.
Increasing the Speed of Ingestion¶
Gluent Query Engine has a number of built-in optimizations that aim to increase the speed of ingestion of rows returned from the backend system to the RDBMS. These are not controllable by the end user and are described here for reference only.
- Projection Optimization
Smart Connector only projects and returns data for columns in the plan projection (for example, selected columns, columns used in join conditions, or columns involved in predicates), thereby reducing the volume of data that needs to be transported from the backend system to the RDBMS. The greatest impact of this optimization is realized when eliminating strings and timestamps from the projection.
- Column Dropout
An optimization whereby Smart Connector returns incomplete records when trailing fields are not in the projection (and therefore not required).
- Run-Length Encoding
Method used by Smart Connector to minimize data returned to hybrid external table interface by replacing sequences of the same data values by a count number and a single value.
- Data Type Conversion
Gluent Query Engine’s Data Daemon (internally or via UDFs) converts backend field values to Oracle Database internal formats for greater efficiency in external table ingestion.
Increasing the Speed of Backend Processing¶
Partition Pruning¶
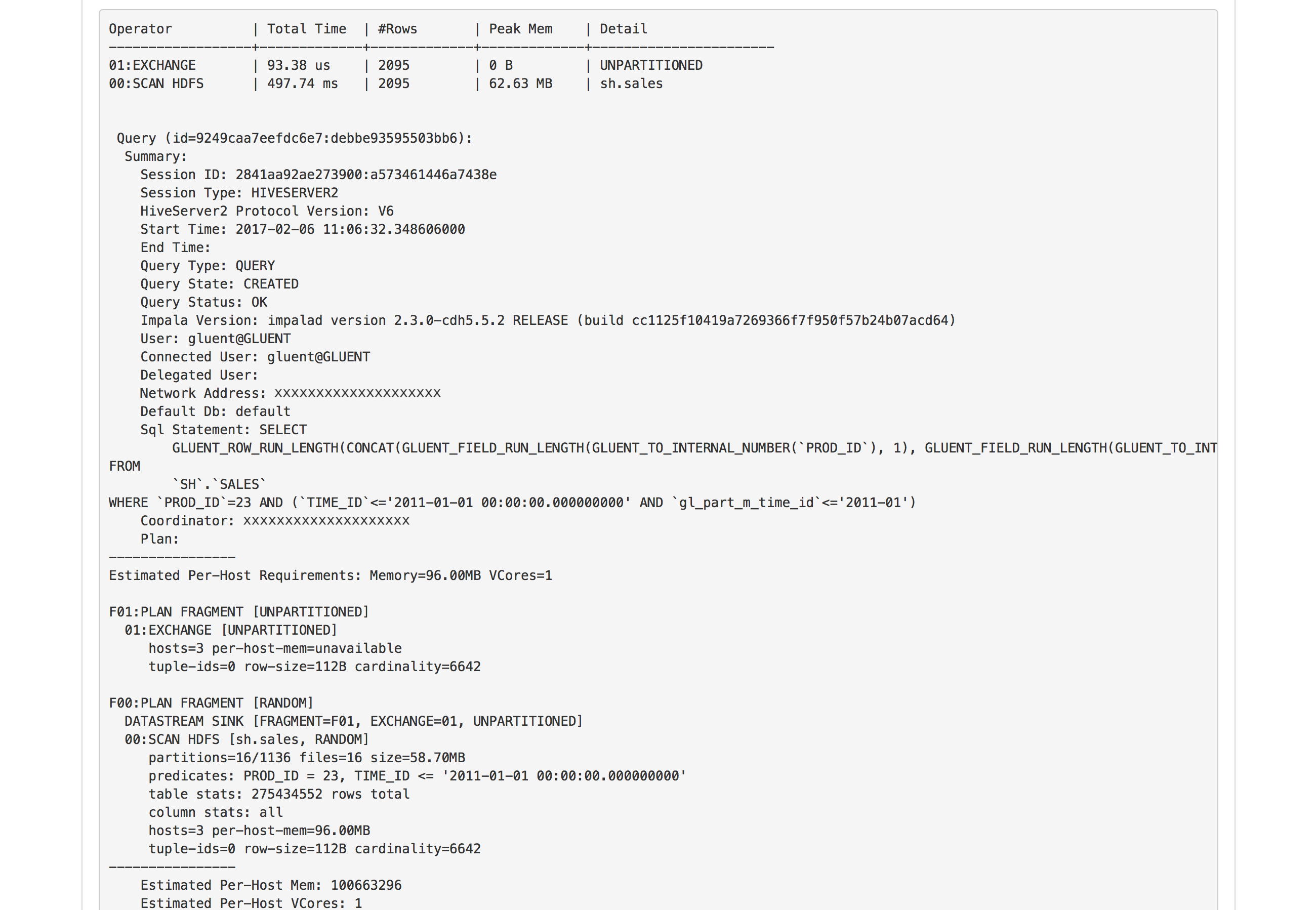
In addition to predicate pushdown the query in Predicate Pushdown also demonstrates partition pruning. The example given is from a BigQuery system, with the SALES table partitioned on the TIME_ID column in both Oracle and BigQuery. Partitioning and partition-pruning is also applicable to Hadoop-based backends. In a Hadoop system, Gluent Offload Engine will partition the backend table by a GL_PART_M_TIME_ID synthetic partition key.
The following image shows the Plan section of a Hybrid Query Report for the example query in a Hadoop environment. Notice that the SQL contains both the TIME_ID predicate and the matching GL_PART_M_TIME_ID synthetic partition key predicate injected by Smart Connector to enable partition pruning. The Plan can be used to determine if partitioning pruning has occurred. The SCAN HDFS operation (under the F00:PLAN FRAGMENT step) shows that Impala has scanned only 16 partitions from a total of 1136:
See also
Synthetic Partitioning for details on synthetic partitioning.
Increasing Throughput from Backend to RDBMS¶
Parallel Query¶
When a hybrid query is executed in parallel, multiple Smart Connector processes are spawned to ingest data independently for each parallel query slave. This parallel resultset ingestion is most useful for queries that need to send 10s or 100s of millions of rows to the RDBMS.
When using Impala as the backend SQL engine, offloaded tables always have a surrogate partition column called OFFLOAD_BUCKET_ID. See Surrogate Partitioning for Bucketing for details of how this is generated. This surrogate key is used by to enable parallel Smart Connectors to read data from Hadoop concurrently. Each Smart Connector process runs its own query in Impala resulting in each one having its own Impala Query Coordinator (QC). In this way the Impala QC is no longer the serial bottleneck when returning the entire resultset to the RDBMS.
Parallel hybrid queries on other SQL engines such as BigQuery, Snowflake or Synapse utilize a result cache. (This is also true for Impala when there is no OFFLOAD_BUCKET_ID surrogate partition column in a presented table or view.) The result cache is created in the backend system and enables parallel Smart Connectors to ingest the data into the RDBMS concurrently.
Tip
Parallel query functionality also provides general support for parallel processing in Oracle Database.
Interpreting a Hybrid Query Report¶
Hybrid Query Report provides a range of information to assist with performance investigations. Some guidance on the main sections of the report and how to interpret them are provided below. Instructions on Hybrid Query Report and how to generate reports is provided in the Utilities guide (see Hybrid Query Report).
There are two sections to the main report:
Oracle’s Real-time SQL Monitoring report
Gluent Data Platform’s hybrid query profile
Oracle’s Real-time SQL Monitoring Report¶
Oracle’s Real-time SQL Monitoring report shows Oracle resource consumption:
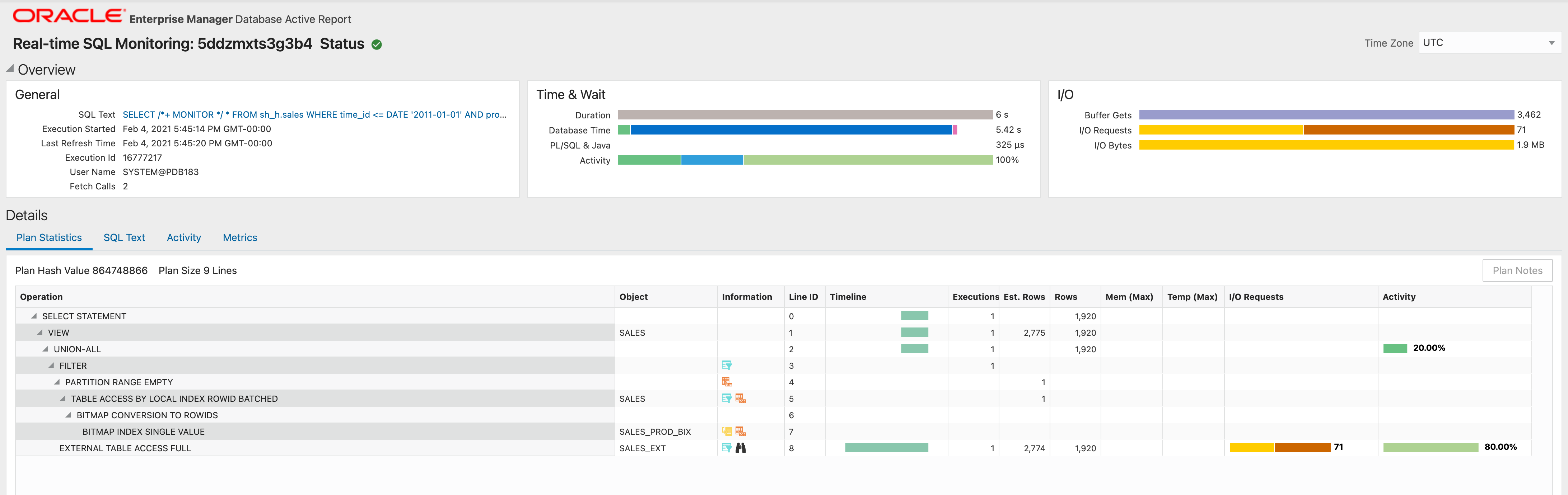
Note:
The query is accessing the SALES hybrid view (90-10)
The data needed from the Oracle Database instance is accessed from the SALES table
The data needed from the backend is accessed from the SALES_EXT hybrid external table
There was a single execution of the EXTERNAL TABLE ACCESS FULL plan line and yielded 1,920 rows (it is possible for this number to be less than the Oracle received figure if predicates that can’t be pushed down are applied by Oracle Database to this plan line)
Gluent Data Platform’s Hybrid Query Profile¶
Gluent Data Platform’s hybrid query profile shows Gluent Query Engine/backend resource consumption:
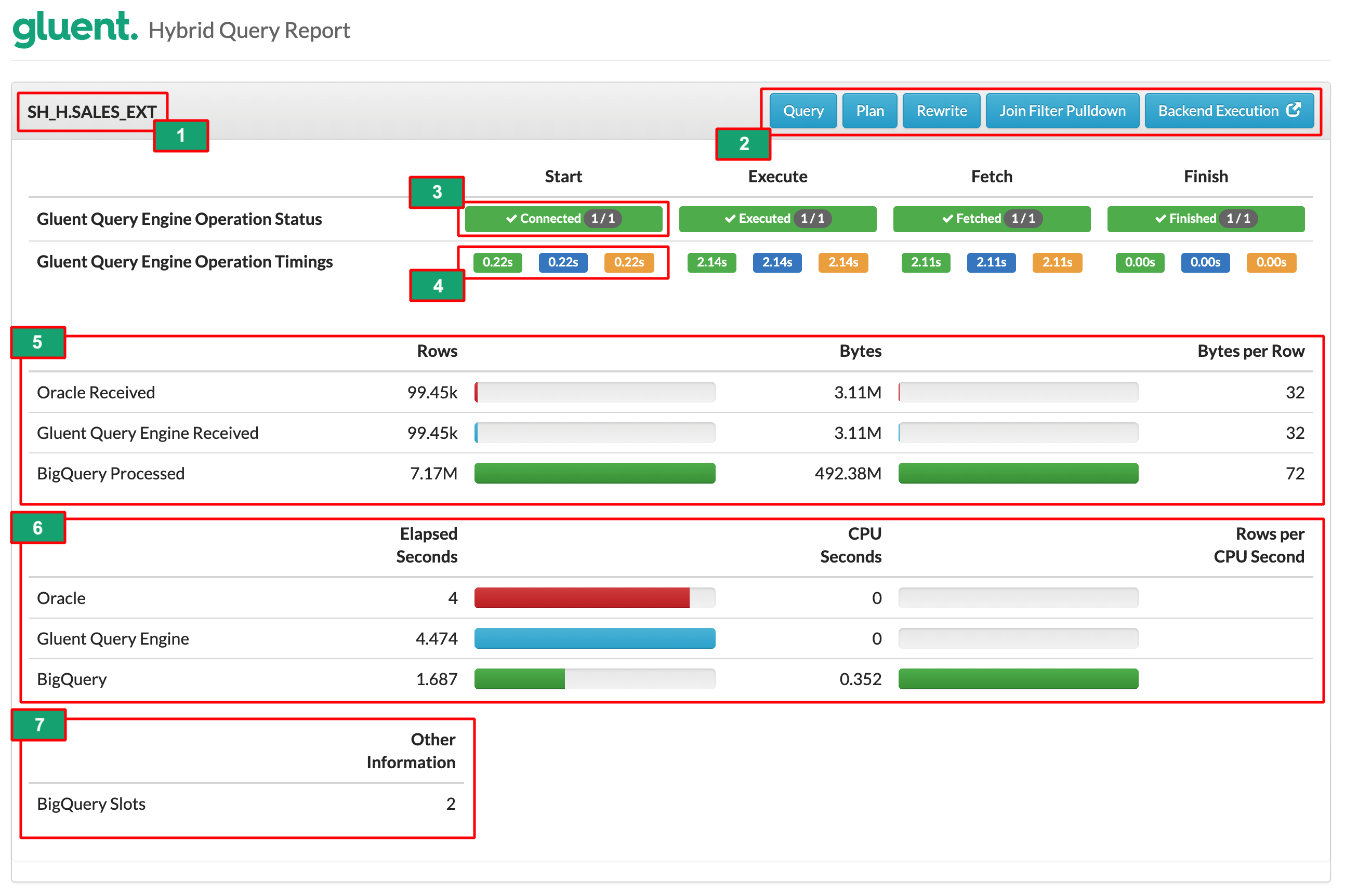
For more details on the numbered items in the image, see:
1. Oracle Database Plan Line Object¶
The Oracle Database plan line hybrid external table name is displayed here.
2. Action Buttons¶
Clicking on an action button displays or hides a collapsible section. These are described below.
Query¶
Displays the backend SQL statement constructed by Gluent Query Engine:
Notes:
Assists in determining if expected predicates were pushed down to the backend
The presence of a
1=1predicate indicates that Gluent Query Engine was unable to push a predicate down
Plan¶
This displays the profile or metrics exposed by the backend.
For Google BigQuery, this will be the Query Statistics profile
For Impala, this is the results of the
PROFILEstatement for one Gluent Query Engine sessionFor Snowflake, this will be the results of an
INFORMATION_SCHEMA.QUERY_HISTORY_BY_SESSIONlookup, together with an execution planFor Azure Synapse Analytics, this will be the results of queries against the
sys.dm_pdw_exec_requestsandsys.dm_pdw_exec_requestsDynamic Management Views
Notes:
Assists in determining the efficiency of the backend operations
Assists in determining if partition pruning has occurred (where applicable)
Rewrite¶
Displays the original SQL and the rewritten SQL that resulted from the application of any rewrite rules.
Notes:
Assists in determining if Advanced Aggregation Pushdown has occurred
Assists in determining if Join Pushdown has occurred
Join Filter Pulldown¶
Details on whether Join Filter Pulldown was applied for the different joins in the query.
Backend Execution¶
For Impala, links to the Impalad Web Interface summary for the Impala query executed.
For BigQuery, links to the query in the query history section of the Google Cloud Platform Console.
For Snowflake, links to the query in the query history section of the Snowflake Web Interface.
For Synapse, links to the query in the SQL requests section of the Microsoft Azure Portal (Synapse Analytics).
3. Gluent Query Engine Operation Status¶
Gluent Query Engine operations can be broken down into four consecutive stages described below. The presence of a green box containing a tick mark indicates that the phase is complete for all processes. The number of Smart Connector processes is shown in the badge. For serial queries this will be 1/1. For parallel queries this will be the number of buckets the table was offloaded with.
- Start
A Smart Connector process is spawned. It requests and receives information from the Metadata Daemon process then constructs the necessary query to be executed in the backend by Data Daemon.
- Execute
The query is passed to the backend SQL engine to be executed.
- Fetch
The data is scanned, filtered, and joined by the backend where necessary. The resulting data is sent back to the RDBMS. This stage is only complete when all of the required rows have been returned.
- Finish
The Smart Connector process cleans up and is terminated.
4. Gluent Query Engine Operation Timings¶
Three timings are given for each stage. Each time is for that stage alone rather than the cumulative time to that point. The green timing is the minimum, the blue is the average, and the orange is the maximum. For serial queries all three timings are the same as they represent a single Smart Connector. For parallel queries the values will be different. This is useful for ensuring that the surrogate key has distributed the data evenly so that each Smart Connector process is processing an equal share of data.
5. Data Transfer Metrics¶
This shows the flow of rows and bytes from Storage → Gluent Query Engine → Oracle Database. Depending on the availability of data in the Impala profile, some older Impala systems will show the flow of rows and bytes from HDFS → Impala QC → Gluent Query Engine → Oracle Database.
- Filtering
If the
Connector Received(andImpala QC Receivedin some Impala systems) figure for rows is present and less than the<backend> Processed/Scannedthen this shows that filtering has occurred. Note that at the time of writing, Snowflake and Synapse do not expose the number of rows that were scanned by a query before filtering/returning, so this metric will be blank on the report.- Network byte inflation
Bytes values will vary according to component. As with rows, the backend will likely scan more bytes than it returns and the bytes processed by Gluent Query Engine and Oracle Database will reflect the filtered results. However, the numbers are not directly comparable. The Oracle Database external table loader must still ingest entire rows, even if they include a large number of columns that are not required. Even if these columns are not going to be used in the rest of the plan the loader still parses and fully ingests them. For Impala backends, Gluent Query Engine pushes the processing overhead of constructing fully encoded external-table rows to the backend including any non-required columns, while on BigQuery, Snowflake and Synapse backends, this is performed by Data Daemon. Null/empty values are returned for non-projected columns, but the byte-cost of non-projected columns can be quite high. The Connector value also includes network protocol overhead.
6. Time Metrics¶
This section shows both elapsed and CPU seconds consumed by the backend engine, Gluent Query Engine and Oracle Database for the external table plan line. The Rows per CPU Second metric is a good indicator of the row ingestion performance.
7. Other Information¶
This section lists any other useful information about the hybrid external table access. At the time of writing, this is currently limited to cloud consumption units such as the number of BigQuery slots or Snowflake credits used to access the data required by the hybrid external table.